
Содержание:
Функция REGEXEXTRACT в Google Таблицах является частью набора функций REGEX, доступного многим пользователям. Эта функция очень удобна, когда вы пытаетесь найти определенную строку, которая является частью более крупной.
Единственное условие для использования этой функции — твердое знание регулярных выражений.
В этом руководстве мы подробно обсудим функцию REGEXEXTRACT, а также несколько примеров того, как вы можете применить их в некоторых общих задачах с электронными таблицами.
Что делает функция REGEXTRACT?
Функция REGEXEXTRACT в основном использует регулярные выражения для извлечения совпадающих подстрок из строки. Она принимает строку и регулярное выражение и возвращает часть строки, которая соответствует шаблону в регулярном выражении.
Синтаксис функции REGEXEXTRACT
Синтаксис функции REGEXTRACT следующий:
REGEXEXTRACT (text; reg_exp)
Здесь,
- text — это текст или строка, из которой вы хотите извлечь подстроку
- reg_exp — регулярное выражение. Выражение соответствует той части текста, которую вы хотите извлечь. Параметр регулярного выражения следует заключать в двойные кавычки.
Примечание: функция всегда возвращает первую часть текста, которая соответствует шаблону в reg_exp.
Приложения функции REGEXTRACT
Функция REGEXEXTRACT может быть весьма полезной, если вы хотите извлечь ценную информацию из набора строк, которые не совсем «однородны» или согласованы по формату.
Вот несколько полезных приложений функции REGEXEXTRACT. Вы можете использовать её следующим образом:
- Извлечь первые или последние несколько символов из строки
- Извлечь числа из строки
- Извлекать целые слова на основе частичного совпадения
- Извлечь одно из списка слов
- Извлечь содержимое между определенными символами
- Извлечь разные части URL
- Извлекайте разные части адресов электронной почты
Давайте посмотрим, как REGEXREPLACE можно использовать в каждом из вышеуказанных приложений.
Использование функции REGEXEXTRACT для извлечения первых или последних символов из строки
Давайте сначала посмотрим, как вы можете использовать REGEXREPLACE для извлечения первых или последних нескольких символов или слов из строки.
Допустим, у вас есть следующий список названий книг в столбце A:
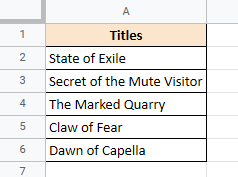
=REGEXEXTRACT(A2,"...")
Вот результат, который вы получите:
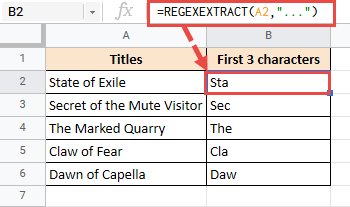
Итак, ваша формула будет такой:
=REGEXEXTRACT(A2,"...$")
Вот результат, который вы получите:
Если вы хотите убедиться, что вы извлекаете только буквенно-цифровые символы, то вместо символа точки вы можете использовать метасимвол w, который представляет один буквенно-цифровой символ (цифру, букву или подчеркивание).
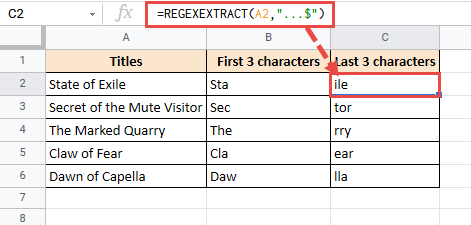
Итак, если вы хотите извлечь первое слово целиком, вам нужно будет использовать комбинацию «w +». Это гарантирует, что любые символы перед первым пробелом будут извлечены следующим образом:
=REGEXEXTRACT(A2,"\w+")
Точно так же, чтобы извлечь последнее слово, формула будет выглядеть так:
=REGEXEXTRACT(A2,"\w+$")
Вот результат, который вы получите:
Использование функции REGEXEXTRACT для извлечения чисел из строки
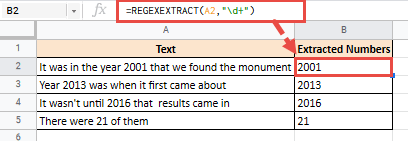
Метасимвол d представляет собой числовую цифру. Таким образом, если вы хотите извлечь первое число из строки, вы можете использовать выражение «d +» следующим образом:
=REGEXEXTRACT(A2,"\d+")
Вот результаты, которые вы получите для следующего списка строк:
Использование функции REGEXTRACT для извлечения целых слов на основе частичного совпадения
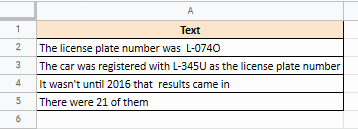
Допустим, у вас есть следующий список строк и вы хотите извлечь все номера автомобильных номеров, которые начинаются с символов ‘L-‘:
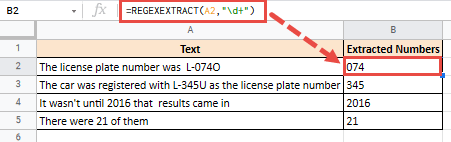
=REGEXEXTRACT(A2,"L-\w+")
Это даст вам следующий результат:

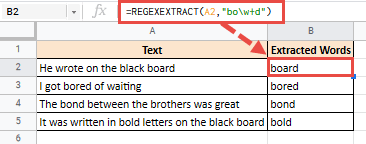
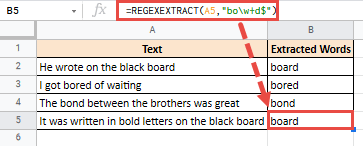
=REGEXEXTRACT(A2,"bo\w+d")
Это даст вам следующий результат:
=REGEXEXTRACT(A2,"bo\w+d$")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения одного из списка слов
Метасимвол «|» представляет собой операцию «OR». Итак, если вы хотите извлечь одно слово из списка слов или символов, вы можете использовать этот символ в функции REGEXMATCH.
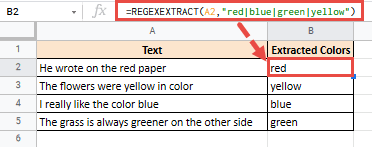
Например, допустим, у вас есть следующий список строк:

=REGEXEXTRACT(A2,"red|blue|green|yellow")
Это даст вам следующий результат:
Использование функции REGEXTRACT для извлечения содержимого между определенными символами
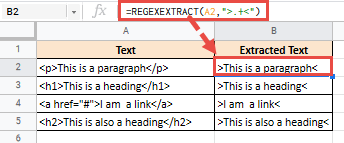
Обычно функция REGEXREPLACE используется для извлечения содержимого между определенными символами. Например, предположим, что вы скопировали некоторый текст разметки с веб-сайта и вам нужно извлечь только его текстовую часть, удалив теги HTML:

= REGEXTRACT (A2; ">. + <")
Однако при этом также будут извлечены символы вместе с текстом между ними, как показано ниже:
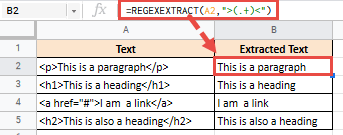
= REGEXTRACT (A2; "> (. +) <")
Это даст вам следующий результат:
Использование функции REGEXEXTRACT для извлечения различных частей URL-адреса
Если вы хотите извлечь доменное имя URL-адреса, вы можете использовать REGEXEXTRACT следующим образом:
=REGEXEXTRACT(A2,"http.+\ / \ /(.+) \ /")
Это извлечет все содержимое между шаблоном HTTP: // (или HTTPS: //) и символом ‘/’.
Приведенная выше формула даст вам следующий результат:
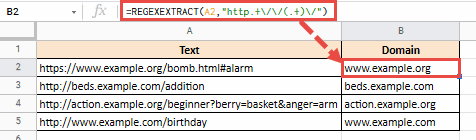
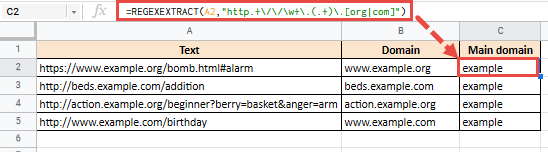
=REGEXEXTRACT(A27,"http.+\ / \ / \ w+\.(.+)\.[org|com]")
Здесь мы убедились, что все слова перед точкой и после нее удалены. Поскольку слово после точки может быть любым из слов org или com, мы указали их в квадратных скобках.
Это даст вам следующий результат:
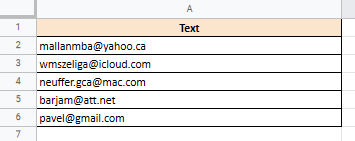
Использование функции REGEXTRACT для извлечения различных частей адреса электронной почты
Как и в предыдущем примере, мы также можем использовать REGEXEXTRACT для извлечения частей адреса электронной почты. Например, предположим, что у вас есть следующий список адресов электронной почты:
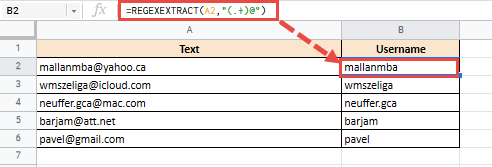
= REGEXTRACT (A33; "(. +) @")
Это даст вам следующий результат:
Если вместо имени пользователя вас больше интересует извлечение части имени домена из адреса электронной почты, вы можете использовать функцию REGEXEXTRACT следующим образом:
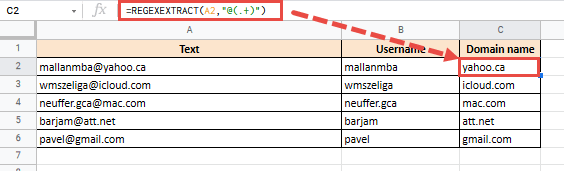
= REGEXTRACT (A33; "@ (. +)")
Это даст вам следующий результат:
Использование функции REGEXTRACT для извлечения определенного шаблона символов
Допустим, у вас есть следующий список строк и вы хотите извлечь номера телефонов из каждой ячейки:
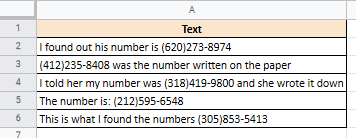
= REGEXTRACT (A40; "(...) ...-....")
Здесь каждая точка представляет один символ. Однако вместо того, чтобы ставить столько точек, вы можете сократить регулярное выражение, поставив за точкой после точки количество символов, заключенных в фигурные скобки.
Поэтому вместо «…» вы можете использовать «. {3}» в своем выражении. Это означает, что приведенная выше формула также может быть записана как:
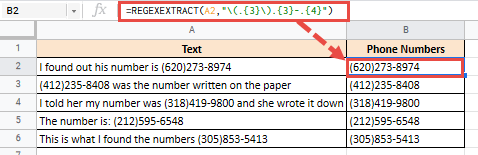
= REGEXTRACT (A40; "(. {3}). {3} -. {4}")
У вас есть 3 числа в круглых скобках, за которыми следуют еще три числа, за ними следует дефис и еще 4 числа.
Это даст вам следующий результат:
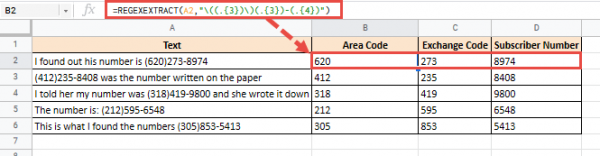
Итак, чтобы разделить результат приведенной выше формулы на три разных столбца, ваша функция REGEXTRACT может быть записана как:
= REGEXTRACT (A40, "((. {3})) (. {3}) - (. {4})")
Это даст вам следующий результат:
REGEXEXTRACT Совет по функциям Google Таблиц:
Вот несколько важных советов, которые необходимо помнить при использовании функции REGEXEXTRACT.
- Эта функция работает только с вводом текста. Не работает с числами
- Если вы хотите использовать числа в качестве входных данных (например, телефонные номера), вам необходимо сначала преобразовать их в текст, используя функцию TEXT.
- Функция REGEXEXTRACT чувствительна к регистру. Следовательно, вам нужно будет указать правильный регистр внутри регулярного выражения или преобразовать всю входную строку в верхний или нижний регистр с помощью функций UPPER или LOWER.
Функция REGEXEXTRACT может иметь множество приложений, если вы научитесь ее эффективно использовать. Хорошее знание регулярных выражений помогает, и лучший способ овладеть им — это попрактиковаться.
Поиграйте с различными регулярными выражениями и посмотрите, какие результаты вы получите. Вы будете удивлены, насколько полезной может быть функция REGEXEXTRACT, когда вы начнете использовать ее для повседневных данных электронной таблицы.